当大模型的参数量开始触及万亿级别,一个古老而又聪明的架构——MoE(混合专家模型)突然被推向聚光灯下。它不再只是学术界论文里的精巧设计,而是实实在在通过API形式向全球开发者开放的生产力工具。对于正在寻找突破口的AI创业者而言,这可能是继GPT之后最值得关注的科技动态。MoE大模型API不仅意味着更低的推理成本、更快的响应速度,还带来了全新的能力组合方式:让多个“专家”模型并行协作,用最小的算力代价完成最复杂的任务。
本文将深入拆解MoE大模型API的技术内核,梳理它如何改变应用的构建逻辑,并探讨在AI创业浪潮中,开发者如何利用这股新势能打造出差异化的产品。
MoE大模型的核心原理与技术突破
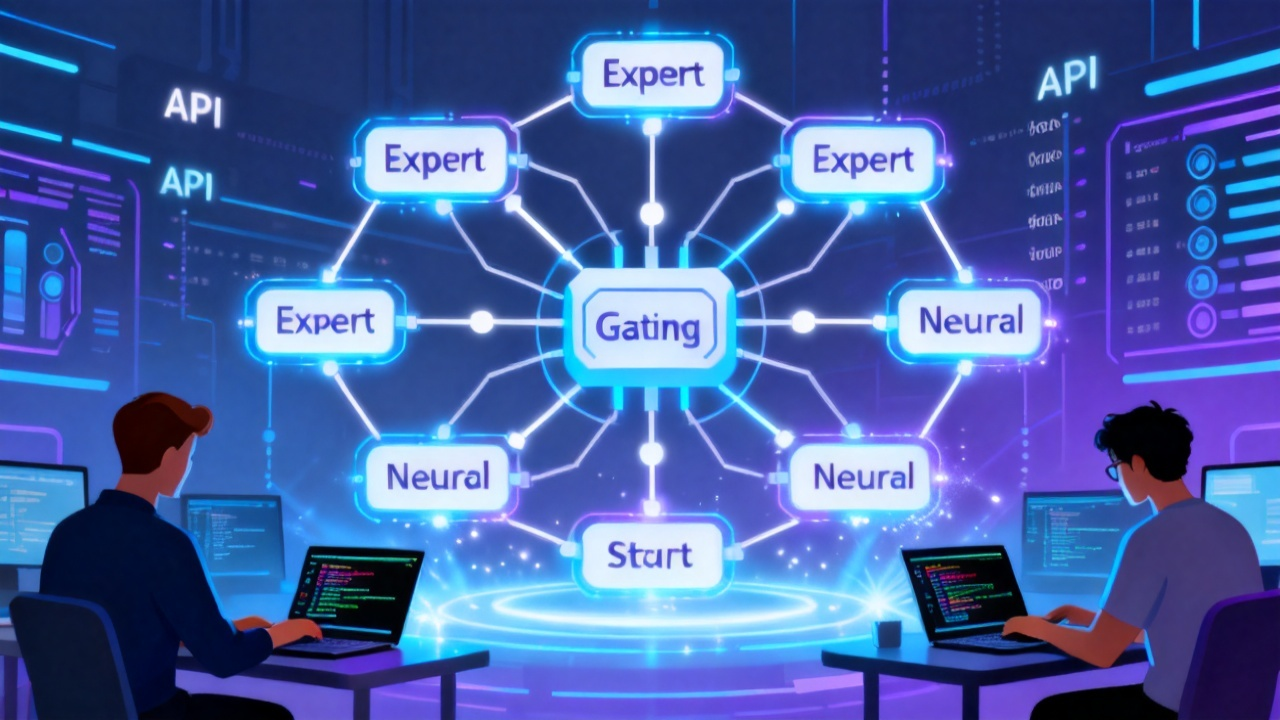
顾名思义,混合专家模型(Mixture of Experts)的核心思想是“分而治之”。一个庞大臃肿的神经网络被拆分成若干个相对独立的“专家”子网络(Expert),并由一个“门控网络”(Gating Network)根据输入的不同特征动态决定激活哪些专家。这种架构最直观的优势在于:推理时只调用部分专家,计算量远低于同等参数量的稠密模型,却保留了几乎全部的表达能力。
2023年以来,无论是Google的Gemini、Mistral AI的Mixtral 8x7B,还是国内多个厂商推出的MoE开源模型,都证明了这一路径的商业价值。在API层面,MoE带来的改变是革命性的。传统大模型API按token计费,用户要为每一个推理请求支付固定费用;而MoE大模型API因为稀疏激活的特性,实际算力消耗显著降低,部分服务商甚至将单次调用价格压到了传统模型的十分之一。
更值得关注的是,MoE架构天然适合多模态和任务分解。以AI画图场景为例,一个MoE模型可以在内部将文本理解任务分配给擅长语义解析的专家,将图像生成任务分配给擅长布局和色彩的专家,最终输出比单一大模型更细腻、更符合用户意图的内容。这种“术业有专攻”的设计思路,正在重构我们对于模型能力的认知。
从API到应用:MoE大模型如何赋能开发者
API是模型能力的封装,也是开发者接入AI的桥梁。MoE大模型API在保持强大基础能力的同时,大幅降低了使用门槛。传统上,开发者调通一个大模型API往往需要处理复杂的参数调优、上下文窗口管理、输出格式控制等问题。而MoE大模型API通过内置的门控机制和专家路由,能够自动适应不同领域的输入,用户甚至不需要指定“我属于哪个领域”。
例如,在构建一个企业知识库问答系统时,如果使用传统大模型,开发者需要手动配置RAG(检索增强生成)流程,甚至需要准备多个不同领域的微调模型。而MoE大模型API自带领域专家:对于财务问题,会优先激活财务专家模块;对于法律咨询,则激活法律专家模块。这相当于将多个垂直模型打包在一个API后面,用一次调用完成过去多次调用才能完成的任务。
这种“一体化”的能力对AI创业公司尤为友好。他们不再需要为每一个垂直场景单独训练或微调模型,而是可以通过一套API覆盖多个业务线。与此同时,不少云厂商开始推出围绕MoE大模型API的工具链,包括AI工具导航等资源聚合平台,帮助开发者快速寻找合适的辅助工具。
AI创业者的新红利:MoE大模型API带来的机遇
对于AI创业者而言,成本、效率和差异化是永远绕不开的三座大山。MoE大模型API的出现,恰好同时触动了这三个变量。首先,在成本端,稀疏激活带来的算力节省直接反映在API价格上。据多家云厂商公布的数据,MoE模型的每token推理成本比同规模稠密模型低约40%~60%。这意味着,创业者可以用相同的预算支撑更多的用户量,或者将省下来的资金投入到产品体验和运营推广上。
其次,在效率端,MoE大模型API的响应延迟已经可以控制在200毫秒以下(针对简单任务),这为实时交互类产品(如AI客服、AI陪聊、AI游戏NPC)提供了技术基础。过去很多AI创业项目因为模型推理太慢而被用户诟病“智能但不流畅”,MoE的快速推理能力正在消除这个痛点。
更重要的是,MoE架构为创业者的“差异化创新”提供了空间。传统大模型API只能输出单一答案,而MoE天然支持多专家协同,开发者可以设计出类似“辩论式输出”的功能:让模型内部的几个专家对同一问题给出不同角度的回答,最后由另一个专家综合判断。这种能力在教育、法律、医疗等需要多维度分析的领域极具价值。
可以说,这一轮AI创业热潮中,率先拥抱MoE大模型API的团队,正在享受从技术红利到商业红利的双重效应。密切关注科技动态的先行者们已经开始用AI诗词等创意工具探索新的交互形态。
行业实践:MoE大模型在创意生产与效率提升中的落地
理论终究要落向现实。目前MoE大模型API已经在多个行业展现出惊人的潜力。在内容创作领域,某知名AI写作工具厂商引入MoE后,将长文生成的中断率降低了35%,因为模型内部的“逻辑专家”和“修辞专家”可以更好协同处理超长文本的连贯性问题。
在设计领域,文生图工具利用MoE架构实现了“风格即时切换”。用户输入一段描述,门控网络自动判断应该激活擅长写实风格还是卡通风格的专家,避免了传统模型中需要反复修改提示词的麻烦。类似地,AI图片生成功能也因为MoE的专家分工而变得更加精准——背景与主体的分离更加自然,光影效果也更加真实。
在效率工具领域,一位创业者分享了他们的案例:用MoE大模型API改造了公司的合同审核系统。过去需要三个不同模型分别处理条款识别、风险评分和合规检查,如今用一个MoE大模型API即可完成,集成成本下降了70%。他特别提到,配合抠图工具和背景去除功能,公司还顺带开发了自动化合同配图模块,实现了从文本到视觉的全链路AI化。
这些实践表明,MoE大模型API已经不再是实验室里的概念验证,而是实实在在地进入了生产环境。对于希望快速迭代产品的团队来说,利用AI工具导航平台发现和组合不同的工具API,已经成为一种高效的开发范式。
挑战与思考:MoE大模型API的局限性与优化方向
尽管前景光明,MoE大模型API并非没有短板。最突出的问题是“专家负载不均衡”。在实际使用中,某些热门领域的专家会被频繁调用,而冷门专家则几乎闲置,这导致整体硬件的利用率低于理论预期。部分API在高峰期会出现响应延迟波动,因为门控网络需要额外计算路由决策。
此外,MoE架构的训练和部署复杂度远高于稠密模型。开发者在调用API时虽然感受不到底层细节,但厂商为此付出的工程成本最终会通过定价机制传导给用户。短期来看,MoE大模型API的价格优势能否持续,取决于能否进一步优化通信开销和显存占用。
另一个隐忧是“黑盒化”。由于多个专家协同工作,当模型输出出现偏差时,很难定位是哪个专家环节出了错误。这对于金融、医疗等对解释性要求较高的行业可能构成障碍。目前已有团队尝试在MoE大模型API中引入可解释性接口,但距离成熟还有距离。
对于AI创业者来说,理解这些局限性有助于合理规划产品路线。例如,在需要高可靠性的场景中,可以同时调用多个MoE API进行投票集成,或者结合大模型训练能力进行定制化微调。
未来展望:从MoE到通用人工智能的进化路径
MoE大模型API的普及,本质上是人工智能从“唯大模型论”向“高效智能”转变的缩影。业内普遍认为,MoE不会是大模型的最终形态,但它是通向通用人工智能(AGI)的重要中间步骤。通过稀疏激活和专家分工,模型可以在不无限扩大参数量和算力消耗的前提下,逐步覆盖更复杂的认知任务。
可以预见,未来的MoE大模型API将具备更强的自适应能力——门控网络可能引入元学习机制,根据用户的长期使用习惯动态调整专家分配策略。同时,结合AI Agent技术,MoE API可以主动拆解用户意图,分配专家子任务,甚至调度外部工具链完成闭环操作。
对于AI创业者来说,现在正是布局的好时机。技术的迭代速度早已超出市场预期,半年后当新一代MoE API支持更精细的专家组合和更低延迟时,今天的竞争者可能已经被甩开一个身位。从艺术签名到AI工具箱,从个人辅助到企业级应用,MoE大模型API正在重塑每一个角落。
在AI创业的版图中,工具和平台的更迭永远是最灵敏的催化剂。而MoE大模型API,正是这个时代最具变革力的一股力量。